1. Integration Points
I haven’t seen a straight-up “website” project since about 1996. Everything is an integration project with some combination of HTML veneer, front-end app, API, mobile app, or all of the above. The context diagram for these projects will fall into one of two patterns: the butterfly or the spider. A butterfly has a central system with a lot of feeds and connections fanning into it on one side and a large fan out on the other side, as shown in the figure that follows.
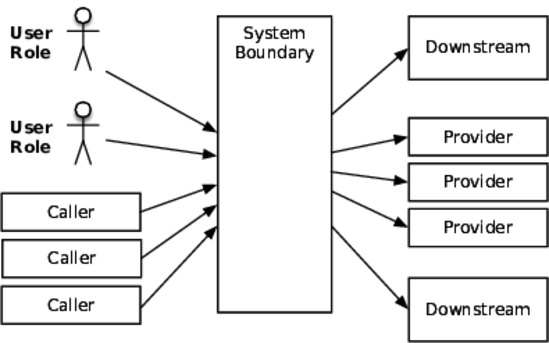
Some people would call this a monolith, but that has negative connotations. It might be a nicely factored system that just has a lot of responsibility.
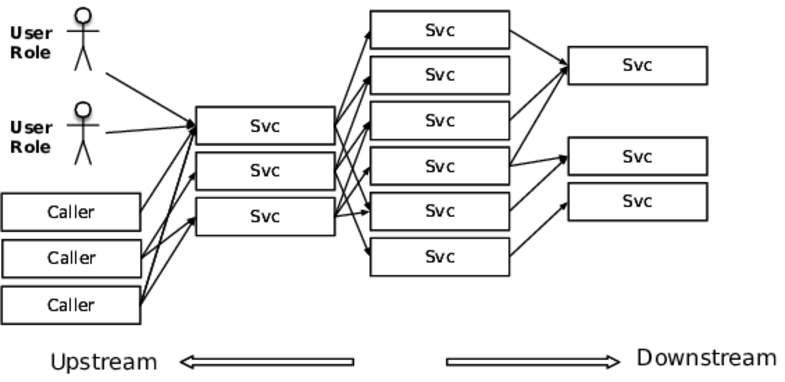
The other style is the spiderweb, with many boxes and dependencies. If you’ve been diligent (and maybe a bit lucky), the boxes fall into ranks with calls through tiers, as shown in the first figure. If not, then the web will be chaotic like that of the black widow, shown in the second figure. The feature common to all of these is that the connections outnumber the services. A butterfly style has 2N connections, a spiderweb might have up to ![]() , and yours falls somewhere in between.
, and yours falls somewhere in between.
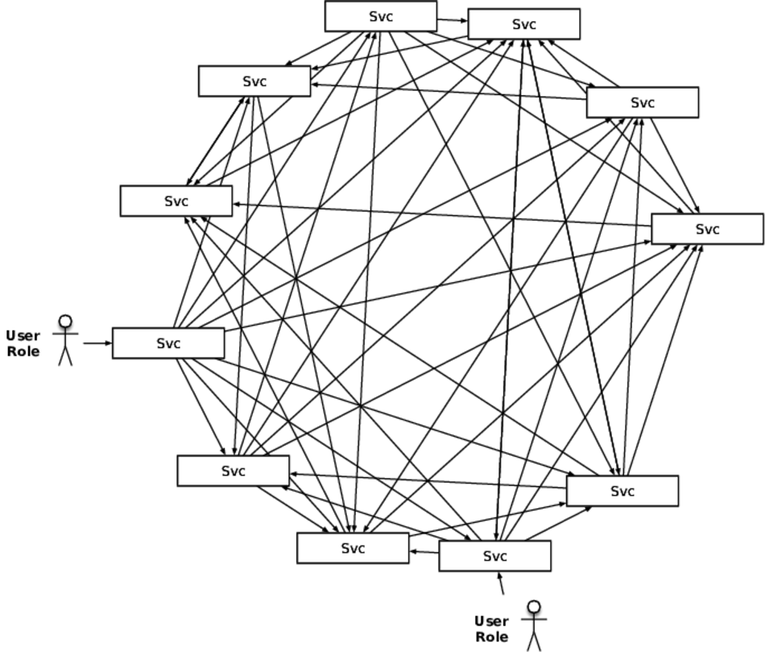
All these connections are integration points, and every single one of them is out to destroy your system. In fact, the more we move toward a large number of smaller services, the more we integrate with SaaS providers, and the more we go API first, the worse this is going to get.
Socket-Based Protocols
Many higher-level integration protocols run over sockets. In fact, pretty much everything except named pipes and shared-memory IPC is socket-based. The higher protocols introduce their own failure modes, but they’re all susceptible to failures at the socket layer.
The simplest failure mode occurs when the remote system refuses connections. The calling system must deal with connection failures. Usually, this isn’t much of a problem, since everything from C to Java to Elm has clear ways to indicate a connection failure—either an exception in languages that have them or a magic return value in ones that don’t. Because the API makes it clear that connections don’t always work, programmers deal with that case.
The figure shows the “three-way handshake” that TCP defines to open a connection.
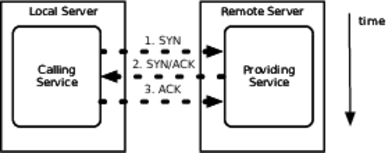
The connection starts when the caller (the client in this scenario, even though it is itself a server for other applications) sends a SYN packet to a port on the remote server. If nobody is listening to that port, the remote server immediately sends back a TCP “reset” packet to indicate that nobody’s home. The calling application then gets an exception or a bad return value.
Suppose, though, that the remote application is listening to the port but is absolutely hammered with connection requests, until it can no longer service the incoming connections. The port itself has a “listen queue” that defines how many pending connections (SYN sent, but no SYN/ACK replied) are allowed by the network stack. Once that listen queue is full, further connection attempts are refused quickly. The listen queue is the worst place to be. While the socket is in that partially formed state, whichever thread called open is blocked inside the OS kernel until the remote application finally gets around to accepting the connection or until the connection attempt times out. Connection timeouts vary from one operating system to another, but they’re usually measured in minutes! The calling application’s thread could be blocked waiting for the remote server to respond for ten minutes!
Nearly the same thing happens when the caller can connect and send its request but the server takes a long time to read the request and send a response. The read call will just block until the server gets around to responding. Often, the default is to block forever. You have to set the socket timeout if you want to break out of the blocking call. In that case, be prepared for an exception when the timeout occurs.
Firewall:
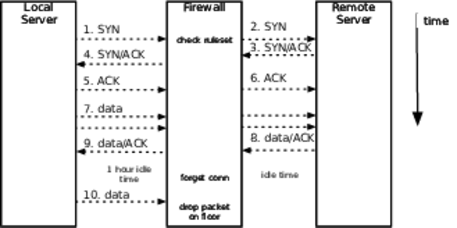
A firewall is nothing but a specialized router. It routes packets from one set of physical ports to another. Inside each firewall, a set of access control lists define the rules about which connections it will allow. The rules say such things as “connections originating from 192.0.2.0/24 to 192.168.1.199 port 80 are allowed.” When the firewall sees an incoming SYN packet, it checks it against its rule base. The packet might be allowed (routed to the destination network), rejected (TCP reset packet sent back to origin), or ignored (dropped on the floor with no response at all). If the connection is allowed, then the firewall makes an entry in its own internal table that says something like “192.0.2.98:32770 is connected to 192.168.1.199:80.” Then all future packets, in either direction, that match the endpoints of the connection are routed between the firewall’s networks.
The key is that table of established connections inside the firewall. It’s finite. Therefore, it does not allow infinite duration connections, even though TCP itself does allow them. Along with the endpoints of the connection, the firewall also keeps a “last packet” time. If too much time elapses without a packet on a connection, the firewall assumes that the endpoints are dead or gone. It just drops the connection from its table, as shown in the following figure. But TCP was never designed for that kind of intelligent device in the middle of a connection. There’s no way for a third party to tell the endpoints that their connection is being torn down. The endpoints assume their connection is valid for an indefinite length of time, even if no packets are crossing the wire.
HTTP Protocols
all HTTP-based protocols use sockets, so they are vulnerable to all of the problems described previously. HTTP adds its own set of issues, mainly centered around the various client libraries. Let’s consider some of the ways that such an integration point can harm the caller:
The provider may accept the TCP connection but never respond to the HTTP request.
The provider may accept the connection but not read the request. If the request body is large, it might fill up the provider’s TCP window. That causes the caller’s TCP buffers to fill, which will cause the socket write to block. In this case, even sending the request will never finish.
The provider may send back a response status the caller doesn’t know how to handle. Like “418 I’m a teapot.” Or more likely, “451 Resource censored.”
The provider may send back a response with a content type the caller doesn’t expect or know how to handle, such as a generic web server 404 page in HTML instead of a JSON response. (In an especially pernicious example, your ISP may inject an HTML page when your DNS lookup fails.)
The provider may claim to be sending JSON but actually sending plain text. Or kernel binaries. Or Weird Al Yankovic MP3s.
Remember This
- Beware this necessary evil.
Every integration point will eventually fail in some way, and you need to be prepared for that failure.
- Prepare for the many forms of failure.
Integration point failures take several forms, ranging from various network errors to semantic errors. You will not get nice error responses delivered through the defined protocol; instead, you’ll see some kind of protocol violation, slow response, or outright hang.
- Know when to open up abstractions.
Debugging integration point failures usually requires peeling back a layer of abstraction. Failures are often difficult to debug at the application layer because most of them violate the high-level protocols. Packet sniffers and other network diagnostics can help.
- Failures propagate quickly.
Failure in a remote system quickly becomes your problem, usually as a cascading failure when your code isn’t defensive enough.
- Apply patterns to avert integration point problems.
Defensive programming via Circuit Breaker, Timeouts \, Decoupling Middleware, and Handshaking will all help you avoid the dangers of integration points.
Chain Reactions:
Remember This
- Recognize that one server down jeopardizes the rest.
A chain reaction happens because the death of one server makes the others pick up the slack. The increased load makes them more likely to fail. A chain reaction will quickly bring an entire layer down. Other layers that depend on it must protect themselves, or they will go down in a cascading failure.
- Hunt for resource leaks.
Most of the time, a chain reaction happens when your application has a memory leak. As one server runs out of memory and goes down, the other servers pick up the dead one’s burden. The increased traffic means they leak memory faster.
- Hunt for obscure timing bugs.
Obscure race conditions can also be triggered by traffic. Again, if one server goes down to a deadlock, the increased load on the others makes them more likely to hit the deadlock too.
- Use Autoscaling.
In the cloud, you should create health checks for every autoscaling group. The scaler will shut down instances that fail their health checks and start new ones. As long as the scaler can react faster than the chain reaction propagates, your service will be available.
- Defend with Bulkheads.
Partitioning servers with Bulkheads, can prevent chain reactions from taking out the entire service—though they won’t help the callers of whichever partition does go down. Use Circuit Breaker on the calling side for that.
Users:
Remember This
- Users consume memory.
Each user’s session requires some memory. Minimize that memory to improve your capacity. Use a session only for caching so you can purge the session’s contents if memory gets tight.
- Users do weird, random things.
Users in the real world do things that you won’t predict (or sometimes understand). If there’s a weak spot in your application, they’ll find it through sheer numbers. Test scripts are useful for functional testing but too predictable for stability testing. Look into fuzzing toolkits, property-based testing, or simulation testing.
- Malicious users are out there.
Become intimate with your network design; it should help avert attacks. Make sure your systems are easy to patch—you’ll be doing a lot of it. Keep your frameworks up-to-date, and keep yourself educated.
- Users will gang up on you.
Sometimes they come in really, really big mobs. When Taylor Swift tweets about your site, she’s basically pointing a sword at your servers and crying, “Release the legions!” Large mobs can trigger hangs, deadlocks, and obscure race conditions. Run special stress tests to hammer deep links or hot URLs.
No comments:
Post a Comment