DATA IN TRANSIT
Encryption helps you achieve confidentiality. A cryptographic operation makes sure that the encrypted data is visible only to the intended recipient. TLS is the most popular way of protecting data for confidentiality in transit. If one microservice talks to another over HTTPS, you’re using TLS underneath, and only the recipient microservice will be able to view the data in cleartext.
Then again, the protection provided by TLS is point to point. At the point where the TLS connection terminates, the security ends. If your client application connects to a microservice over a proxy server, your first TLS connection terminates at the proxy server, and a new TLS connection is established between the proxy server and the microservice. The risk is that anyone who has access to the proxy server can log the messages in cleartext as soon as the data leaves the first connection.
Most proxy servers support two modes of operation with respect to TLS: TLS bridging and TLS tunneling. TLS bridging terminates the first TLS connection at the proxy server, and creates a new TLS connection between the proxy server and the next destination of the message. If your proxy server uses TLS bridging, don’t trust it and possibly put your data at risk, even though you use TLS (or HTTPS). If you use TLS bridging, the messages are in cleartext while transiting through the proxy server. TLS tunneling creates a tunnel between your client application and the microservices, and no one in the middle will be able to see what’s going through, not even the proxy server. If you are interested in reading more about TLS, we recommend having a look at SSL and TLS: Designing and Building Secure Systems by Eric Rescorla (Addison-Wesley Professional, 2000).
The network perimeter level is where you should have the best defense against DoS/DDoS attacks. A firewall is one option; it runs at the edge of the network and can be used to keep malicious users away. But firewalls can’t protect you completely from a DDoS attack. Specialized vendors provide DDoS prevention solutions for use outside corporate firewalls. You need to worry about those solutions only if you expose your system to the internet. Also, all the DDoS protection measures you take at the edge aren’t specific to microservices. Any endpoint that’s exposed to the internet must be protected from DoS/DDoS attacks.
Edge security
A typical microservices deployment with an API gateway: the API gateway is the entry point, which screens all incoming messages for security.
1 Microservices security landscape
- Why microservices security is challenging
- Principles and key elements of a microservices security design
- Edge security and the role of an API gateway
- Patterns and practices in securing service-to-service communications
Fail fast, fail often is a mantra in Silicon Valley. Not everyone agrees, but we love it! It’s an invitation to experiment with new things, accept failures, fix problems, and try again. Not everything in ink looks pretty in practice. Fail fast, fail often is only hype unless the organizational leadership, the culture, and the technology are present and thriving.
We find microservices to be a key enabler for fail fast, fail often. Microservices architecture has gone beyond technology and architectural principles to become a culture. Netflix, Amazon, Lyft, Uber, and eBay are the front-runners in building that culture. Neither the architecture nor the technology behind microservices--but the discipline practiced in an organizational culture--lets your team build stable products, deploy them in a production environment with less hassle, and introduce frequent changes with no negative impact on the overall system.
Speed to production and evolvability are the two key outcomes of microservices architecture. International Data Corporation (IDC) has predicted that by 2022, 90% of all apps will feature microservices architectures that improve the ability to design, debug, update, and leverage third-party code.1
We assume that you’re well versed in microservices design principles, applications, and benefits. If you’re new to microservices and have never been (or are only slightly) involved in development projects, we recommend that you read a book on microservices first, such as Spring Microservices in Action by John Carnell (Manning, 2017). Microservices Patterns by Chris Richardson (Manning, 2018) and Microservices in Action by Morgan Bruce and Paulo A. Pereira (Manning, 2018) are two other good books on the subject. Microservices for the Enterprise: Designing, Developing, and Deploying by Prabath Siriwardena (a coauthor of this book) and Kasun Indrasiri (Apress, 2018) is another beginner’s book on microservices.
In this book, we focus on microservices security. When you make the decision to go ahead with microservices architecture to build all your critical business operations, security is of topmost importance. A security breach could result in many unpleasant outcomes, from losing customer confidence to bankruptcy. Emphasis on security today is higher than at any time in the past. Microservices are becoming key enablers of digital transformation, so microservices security must be consciously planned, designed, and implemented.
This book introduces you to the key fundamentals, security principles, and best practices involved in securing microservices. We’ll be using industry-leading open source tools along with Java code samples developed with Spring Boot for demonstrations. You may pick better, competitive tools later in your production environment, of course.
This book will give you a good understanding of how to implement microservices security concepts in real life, even if you’re not a Java developer. If you’re familiar with any object-oriented programming language (such as C++ or C#) and understand basic programming constructs well, you’ll still enjoy reading the book, even though its samples are in Java. Then again, security is a broader topic. It’s a discipline with multiple subdisciplines. In this book, we mostly focus on application developers and architects who worry about managing access to their microservices. Access management itself is another broader subdiscipline of the larger security discipline. We do not focus on pen testing, developing threat models, firewalls, system-level configurations to harden security, and so on.
1.1 How security works in a monolithic application
A monolithic application has few entry points. An entry point for an application is analogous to a door in a building. Just as a door lets you into a building (possibly after security screening), an application entry point lets your requests in.
Think about a web application (see figure 1.1) running on the default HTTP port 80 on a server carrying the IP address 192.168.0.1. Port 80 on server 192.168.0.1 is an entry point to that web application. If the same web application accepts HTTPS requests on the same server on port 443, you have another entry point. When you have more entry points, you have more places to worry about securing. (You need to deploy more soldiers when you have a longer border to protect, for example, or to build a wall that closes all entry points.) The more entry points to an application, the broader the attack surface is.
Most monolithic applications have only a couple of entry points. Not every component of a monolithic application is exposed to the outside world and accepts requests directly.
In a typical Java Platform, Enterprise Edition (Java EE) web application such as the one in figure 1.1, all requests are scanned for security at the application level by a servlet filter.2 This security screening checks whether the current request is associated with a valid web session and, if not, challenges the requesting party to authenticate first.

Figure 1.1 A monolithic application typically has few entry points. Here, there are two: ports 80 and 443.
Further access-control checks may validate that the requesting party has the necessary permissions to do what they intend to do. The servlet filter (the interceptor) carries out such checks centrally to make sure that only legitimate requests are dispatched to the corresponding components. Internal components need not worry about the legitimacy of the requests; they can rightly assume that if a request lands there, all the security checks have already been done.
In case those components need to know who the requesting party (or user) is or to find other information related to the requesting party, such information can be retri-eved from the web session, which is shared among all the components (see figure 1.2). The servlet filter injects the requesting-party information into the web session during the initial screening process, after completing authentication and authorization.
Once a request is inside the application layer, you don’t need to worry about security when one component talks to another. When the Order Processing component talks to the Inventory component, for example, you don’t necessarily need to enforce any additional security checks (but, of course, you can if you need to enforce more granular access-control checks at the component level). These are in-process calls and in most cases are hard for a third party to intercept.

Figure 1.2 Multiple entry points (ports 80 and 443) are funneled to a single servlet filter. The filter acts as a centralized policy enforcement point.
In most monolithic applications, security is enforced centrally, and individual components need not worry about carrying out additional checks unless there is a desperate requirement to do so. As a result, the security model of a monolithic application is much more straightforward than that of an application built around microservices architecture.
1.2 Challenges of securing microservices
Mostly because of the inherent nature of microservices architecture, security is challenging. In this section, we discuss the challenges of securing microservices without discussing in detail how to overcome them. In the rest of the book, we discuss multiple ways to address these challenges.
1.2.1 The broader the attack surface, the higher the risk of attack
In a monolithic application, communication among internal components happens within a single process--in a Java application, for example, within the same Java Virtual Machine (JVM). Under microservices architecture, those internal components are designed as separate, independent microservices, and those in-process calls among internal components become remote calls. Also, each microservice now independently accepts requests or has its own entry points (see figure 1.3).

Figure 1.3 As opposed to a monolithic application with few entry points, a microservices-based application has many entry points that all must be secured.
Instead of a couple of entry points, as in a monolithic application, now you have a large number of entry points. As the number of entry points to the system increases, the attack surface broadens too. This situation is one of the fundamental challenges in building a security design for microservices. Each entry point to each microservice must be protected with equal strength. The security of a system is no stronger than the strength of its weakest link.
1.2.2 Distributed security screening may result in poor performance
Unlike in a monolithic application, each microservice in a microservices deployment has to carry out independent security screening. From the viewpoint of a monolithic application, in which the security screening is done once and the request is dispatched to the corresponding component, having multiple security screenings at the entry point of each microservice seems redundant. Also, while validating requests at each microservice, you may need to connect to a remote security token service (STS). These repetitive, distributed security checks and remote connections could contribute heavily to latency and considerably degrade the performance of the system.
Some do work around this by simply trusting the network and avoiding security checks at each and every microservice. Over time, trust-the-network has become an antipattern, and the industry is moving toward zero-trust networking principles. With zero-trust networking principles, you carry out security much closer to each resource in your network. Any microservices security design must take overall performance into consideration and must take precautions to address any drawbacks.
1.2.3 Deployment complexities make bootstrapping trust among microservices a nightmare
Security aside, how hard would it be to manage 10, 15, or hundreds of independent microservices instead of one monolithic application in a deployment? We have even started seeing microservices deployments with thousands of services talking to each other.
Capital One, one of the leading financial institutions in the United States, announced in July 2019 that its microservices deployment consists of thousands of microservices on several thousands of containers, with thousands of Amazon Elastic Compute Cloud (EC2) instances. Monzo, another financial institution based in the United Kingdom, recently mentioned that it has more than 1,500 services running in its microservices deployment. Jack Kleeman, a backend engineer at Monzo, explains in a blog (http://mng.bz/gyAx) how they built network isolation for 1,500 services to make Monzo more secure. The bottom line is, large-scale microservices deployments with thousands of services have become a reality.
Managing a large-scale microservices deployment with thousands of services would be extremely challenging if you didn’t know how to automate. If the microservices concept had popped up at a time when the concept of containers didn’t exist, few people or organizations would have the guts to adopt microservices. Fortunately, things didn’t happen that way, and that’s why we believe that microservices and containers are a match made in heaven. If you’re new to containers or don’t know what Docker is, think of containers as a way to make software distribution and deployment hassle-free. Microservices and containers (Docker) were born at the right time to complement each other nicely. We talk about containers and Docker later in the book, in chapter 10.
Does the deployment complexity of microservices architecture make security more challenging? We’re not going to delve deep into the details here, but consider one simple example. Service-to-service communication happens among multiple microservices. Each of these communication channels must be protected. You have many options (which we discuss in detail in chapters 6 and 7), but suppose that you use certificates.
Now each microservice must be provisioned with a certificate (and the corresponding private key), which it will use to authenticate itself to another microservice during service-to-service interactions. The recipient microservice must know how to validate the certificate associated with the calling microservice. Therefore, you need a way to bootstrap trust between microservices. Also, you need to be able to revoke certificates (in case the corresponding private key gets compromised) and rotate certificates (change the certificates periodically to minimize any risks in losing the keys unknowingly). These tasks are cumbersome, and unless you find a way to automate them, they’ll be tedious in a microservices deployment.
1.2.4 Requests spanning multiple microservices are harder to trace
Observability is a measure of what you can infer about the internal state of a system based on its external outputs. Logs, metrics, and traces are known as the three pillars of observability.
A log can be any event you record that corresponds to a given service. A log, for example, can be an audit trail that says that the Order Processing microservice accessed the Inventory microservice to update the inventory on April 15th, 2020, at 10:15.12 p.m. on behalf of the user Peter.
Aggregating a set of logs can produce metrics. In a way, metrics reflect the state of the system. In terms of security, the average invalid access requests per hour is a metric, for example. A high number probably indicates that the system is under attack or the first-level defense is weak. You can configure alerts based on metrics. If the number of invalid access attempts for a given microservice goes beyond a preset threshold value, the system can trigger an alert.
Traces are also based on logs but provide a different perspective of the system. Tracing helps you track a request from the point where it enters the system to the point where it leaves the system. This process becomes challenging in a microservices deployment. Unlike in a monolithic application, a request to a microservices deployment may enter the system via one microservice and span multiple microservices before it leaves the system.
Correlating requests among microservices is challenging, and you have to rely on distributed tracing systems like Jaeger and Zipkin. In chapter 5, we discuss how to use Prometheus and Grafana to monitor all the requests coming to a microservices deployment.
1.2.5 Immutability of containers challenges how you maintain service credentials and access-control policies
A server that doesn’t change its state after it spins up is called an immutable server. The most popular deployment pattern for microservices is container based. (We use the terms container and Docker interchangeably in this book, and in this context, both terms have the same meaning.) Each microservice runs in its own container, and as a best practice, the container has to be an immutable server.3 In other words, after the container has spun up, it shouldn’t change any of the files in its filesystem or maintain any runtime state within the container itself.
The whole purpose of expecting servers to be immutable in a microservices deployment is to make deployment clean and simple. At any point, you can kill a running container and create a new one with the base configuration without worrying about runtime data. If the load on a microservice is getting high, for example, you need more server instances to scale horizontally. Because none of the running server instances maintains any runtime state, you can simply spin up a new container to share the load.
What impact does immutability have on security, and why do immutable servers make microservices security challenging? In microservices security architecture, a microservice itself becomes a security enforcement point.4 As a result, you need to maintain a list of allowed clients (probably other microservices) that can access the given microservice, and you need a set of access-control policies.
These lists aren’t static; both the allowed clients and access-control policies get updated. With an immutable server, you can’t maintain such updates in the server’s filesystem. You need a way to get all the updated policies from some sort of policy administration endpoint at server bootup and then update them dynamically in memory, following a push or pull model. In the push model, the policy administration endpoint pushes policy updates to the interested microservices (or security enforcement points). In the pull model, each microservice has to poll the policy administration endpoint periodically for policy updates. Section 1.5.2 explains in detail service-level authorization.
Each microservice also has to maintain its own credentials, such as certificates. For better security, these credentials need to be rotated periodically. It’s fine to keep them with the microservice itself (in the container filesystem), but you should have a way to inject them into the microservice at the time it boots up. With immutable servers, maybe this process can be part of the continuous delivery pipeline, without baking the credentials into the microservice itself.
1.2.6 The distributed nature of microservices makes sharing user context harder
In a monolithic application, all internal components share the same web session, and anything related to the requesting party (or user) is retrieved from it. In microservices architecture, you don’t enjoy that luxury. Nothing is shared among microservices (or only a very limited set of resources), and the user context has to be passed explicitly from one microservice to another. The challenge is to build trust between two microservices so that the receiving microservice accepts the user context passed from the calling microservice. You need a way to verify that the user context passed among microservices isn’t deliberately modified.5
Using a JSON Web Token (JWT) is one popular way to share user context among microservices; we explore this technique in chapter 7. For now, you can think of a JWT as a JSON message that helps carry a set of user attributes from one microservice to another in a cryptographically safe manner.
1.2.7 Polyglot architecture demands more security expertise on each development team
In a microservices deployment, services talk to one another over the network. They depend not on each service’s implementation, but on the service interface. This situation permits each microservice to pick its own programming language and the technology stack for implementation. In a multiteam environment, in which each team develops its own set of microservices, each team has the flexibility to pick the optimal technology stack for its requirements. This architecture, which enables the various components in a system to pick the technology stack that is best for them, is known as a polyglot architecture.
A polyglot architecture makes security challenging. Because different teams use different technology stacks for development, each team has to have its own security experts. These experts should take responsibility for defining security best practices and guidelines, research security tools for each stack for static code analysis and dynamic testing, and integrate those tools into the build process. The responsibilities of a centralized, organization-wide security team are now distributed among different teams. In most cases, organizations use a hybrid approach, with a centralized security team and security-focused engineers on each team who build microservices.
1.3 Key security fundamentals
Adhering to fundamentals is important in any security design. There’s no perfect or unbreakable security. How much you should worry about security isn’t only a technical decision, but also an economic decision. There’s no point in having a burglar-alarm system to secure an empty garage, for example. The level of security you need depends on the assets you intend to protect. The security design of an e-commerce application could be different from that of a financial application.
In any case, adhering to security fundamentals is important. Even if you don’t foresee some security threats, following the fundamentals helps you protect your system against such threats. In this section, we walk you through key security fundamentals and show you how they’re related to microservices security.
1.3.1 Authentication protects your system against spoofing
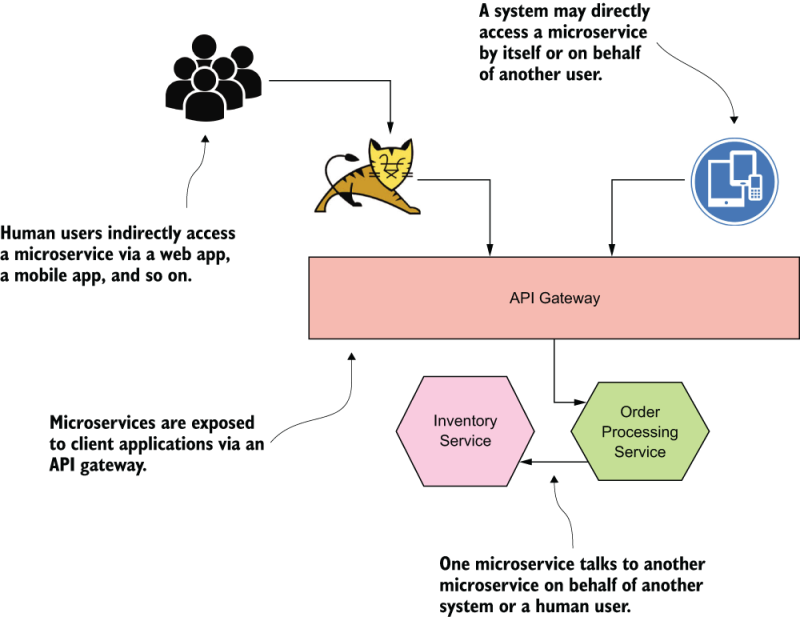
Authentication is the process of identifying the requesting party to protect your system against spoofing. The requesting party can be a system (a microservice) or a system requesting access on behalf of a human user or another system (see figure 1.4). It’s rather unlikely that a human user will access a microservice directly, though. Before creating a security design for a given system, you need to identify the audience. The authentication method you pick is based on the audience.

Figure 1.4 A system (for example, a web/mobile application), just by being itself or on behalf of a human user or another system, can access microservices via an API gateway.
If you’re worried about a system accessing a microservice on behalf of a human user, you need to think about how to authenticate the system as well as the human user. In practice, this can be a web application, which is accessing a microservice, on behalf of a human user who logs into the web application. In these kinds of delegated use cases, in which a system requests access on behalf of another system or a human user, OAuth 2.0 is the de facto standard for security. We discuss OAuth 2.0 in detail in appendix A.
To authenticate the human user to a system (for example, a web application), you could request the username and password with another factor for multifactor authentication (MFA). Whether MFA is required is mostly a business decision, based on how critical your business assets are or how sensitive the data you want to share with users. The most popular form of MFA is the one-time passcode (OTP) sent over SMS. Even though it’s not the best method in terms of security, it’s the most usable form of MFA, mostly because a large portion of the world population has access to mobile phones (which don’t necessarily need to be smartphones). MFA helps reduce account breaches by almost 99.99%.6 Much stronger forms of MFA include biometrics, certificates, and Fast Identity Online (FIDO).
You have multiple ways to authenticate a system. The most popular options are certificates and JWTs. We discuss both these options in detail, with a set of examples, in chapters 6 and 7.
1.3.2 Integrity protects your system from data tampering
When you transfer data from your client application to a microservice or from one microservice to another microservice--depending on the strength of the communication channel you pick--an intruder could intercept the communication and change the data for their advantage. If the channel carries data corresponding to an order, for example, the intruder could change its shipping address to their own. Systems protected for integrity don’t ignore this possibility; they introduce measures so that if a message is altered, the recipient can detect and discard the request.
The most common way to protect a message for integrity is to sign it. Any data in transit over a communication channel protected with Transport Layer Security (TLS), for example, is protected for integrity. If you use HTTPS for communications among microservices (that communication is, in fact, HTTP over TLS), your messages are protected for integrity while in transit.
Along with the data in transit, the data at rest must be protected for integrity. Of all your business data, audit trails matter most for integrity checks. An intruder who gets access to your system would be happiest if they could modify your audit trails to wipe out any evidence. In a microservices deployment based on containers, audit logs aren’t kept at each node that runs the microservice; they’re published in some kind of a distributed tracing system like Jaeger or Zipkin. You need to make sure that the data maintained in those systems is protected for integrity.
One way is to periodically calculate the message digests of audit trails, encrypt them, and store them securely. In a research paper, Gopalan Sivathanu, Charles P. Wright, and Erez Zadok of Stony Brook University highlight the causes of integrity violations in storage and present a survey of available integrity assurance techniques.7 The paper explains several interesting applications of storage integrity checking; apart from security it also discusses implementation issues associated with those techniques.
1.3.3 Nonrepudiation: Do it once, and you own it forever
Nonrepudiation is an important aspect of information security that prevents you from denying anything you’ve done or committed. Consider a real-world example. When you lease an apartment, you agree to terms and conditions with the leasing company. If you leave the apartment before the end of the lease, you’re obliged to pay the rent for the remaining period or find another tenant to sublease the apartment. All the terms are in the leasing agreement, which you accept by signing it. After you sign it, you can’t dispute the terms and conditions to which you agreed. That’s nonrepudiation in the real world. It creates a legal obligation. Even in the digital world, a signature helps you achieve nonrepudiation; in this case, you use a digital signature.
In an e-commerce application, for example, after a customer places an order, the Order Processing microservice has to talk to the Inventory microservice to update inventory. If this transaction is protected for nonrepudiation, the Order Processing microservice can’t later deny that it updated inventory. If the Order Processing microservice signs a transaction with its private key, it can’t deny later that the transaction was initiated from that microservice. With a digital signature, only the owner of the corresponding private key can generate the same signature; so make sure that you never lose the key!
Validating the signature alone doesn’t help you achieve nonrepudiation, however. You also need to make sure that you record transactions along with the timestamp and the signature--and maintain those records for a considerable amount of time. In case the initiator disputes a transaction later, you’ll have it in your records.
1.3.4 Confidentiality protects your systems from unintended information disclosure
When you send order data from a client application to the Order Processing microservice, you expect that no party can view the data other than the Order Processing microservice itself. But based on the strength of the communication channel you pick, an intruder can intercept the communication and get hold of the data. Along with the data in transit, the data at rest needs to be protected for confidentiality (see figure 1.5). An intruder who gets access to your data storage or backups has direct access to all your business-critical data unless you’ve protected it for confidentiality.

Figure 1.5 To protect a system for confidentiality, both the data in transit and at rest must be protected. The data in transit can be protected with TLS, and data at rest can be protected by encryption.
Encryption helps you achieve confidentiality. A cryptographic operation makes sure that the encrypted data is visible only to the intended recipient. TLS is the most popular way of protecting data for confidentiality in transit. If one microservice talks to another over HTTPS, you’re using TLS underneath, and only the recipient microservice will be able to view the data in cleartext.
Then again, the protection provided by TLS is point to point. At the point where the TLS connection terminates, the security ends. If your client application connects to a microservice over a proxy server, your first TLS connection terminates at the proxy server, and a new TLS connection is established between the proxy server and the microservice. The risk is that anyone who has access to the proxy server can log the messages in cleartext as soon as the data leaves the first connection.
Most proxy servers support two modes of operation with respect to TLS: TLS bridging and TLS tunneling. TLS bridging terminates the first TLS connection at the proxy server, and creates a new TLS connection between the proxy server and the next destination of the message. If your proxy server uses TLS bridging, don’t trust it and possibly put your data at risk, even though you use TLS (or HTTPS). If you use TLS bridging, the messages are in cleartext while transiting through the proxy server. TLS tunneling creates a tunnel between your client application and the microservices, and no one in the middle will be able to see what’s going through, not even the proxy server. If you are interested in reading more about TLS, we recommend having a look at SSL and TLS: Designing and Building Secure Systems by Eric Rescorla (Addison-Wesley Professional, 2000).
NOTE Encryption has two main flavors: public-key encryption and symmetric-key encryption. With public-key encryption, the data is encrypted using the recipient’s public key, and only the party who owns the corresponding private key can decrypt the message and see what’s in it. With symmetric-key encryption, the data is encrypted with a key known to both the sender and the recipient. TLS uses both flavors. Symmetric-key encryption is used to encrypt the data, while public-key encryption is used to encrypt the key used in symmetric-key encryption. If you are interested in reading more about encryption and cryptography, we recommend having a look at Real-World Cryptography by David Wong (Manning, to be published in 2021).
Encryption should also apply to data at rest to protect it from intruders who get direct access to the system. This data can be credentials for other systems stored in the filesystem or business-critical data stored in a database. Most database management systems provide features for automatic encryption, and disk-level encryption features are available at the operating-system level. Application-level encryption is another option, in which the application itself encrypts the data before passing it over to the filesystem or to a database.
Of all these options, the one that best fits your application depends on the criticality of your business operations. Also keep in mind that encryption is a resource-intensive operation that would have considerable impact on your application’s performance unless you find the optimal solution.8
1.3.5 Availability: Keep the system running, no matter what
The whole point of building any kind of a system is to make it available to its users. Every minute (or even second) that the system is down, your business loses money. Amazon was down for 20 minutes in March 2016, and the estimated revenue loss was $3.75 million. In January 2017, more than 170 Delta Airlines flights were canceled because of a system outage, which resulted in an estimated loss of $8.5 million.
It’s not only the security design of a system that you need to worry about to keep a system up and running, but also the overall architecture. A bug in the core functionality of an application can take the entire system down. To some extent, these kinds of situations are addressed in the core design principles of microservices architecture. Unlike in monolithic applications, in a microservices deployment, the entire system won’t go down if a bug is found in one component or microservice. Only that microservice will go down; the rest should be able to function.
Of all the factors that can take a system down, security has a key role to play in making a system constantly available to its legitimate stakeholders. In a microservices deployment, with many entry points (which may be exposed to the internet), an attacker can execute a denial-of-service (DoS) or a distributed denial-of-service (DDoS) attack and take the system down.
Defenses against such attacks can be built on different levels. On the application level, the best thing you could do is reject a message (or a request) as soon as you find that it’s not legitimate. Having layered security architecture helps you design each layer to take care of different types of attacks and reject an attacker at the outermost layer.
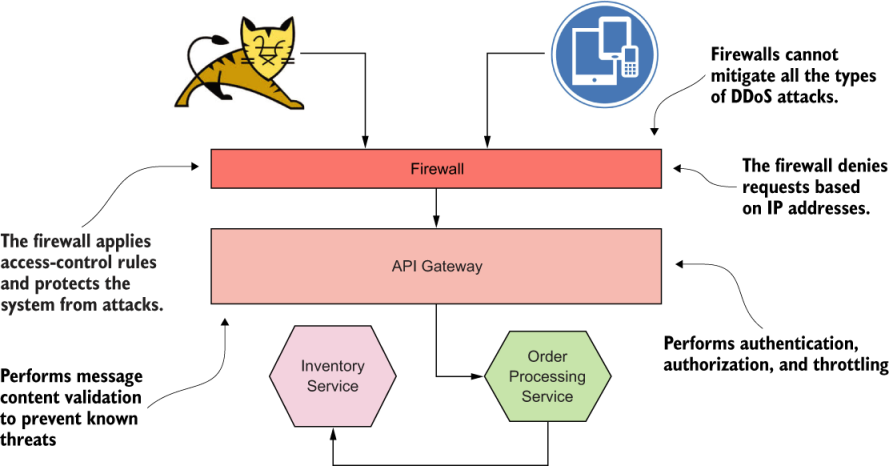
As shown in figure 1.6, any request to a microservice first has to come through the API gateway. The API gateway centrally enforces security for all the requests entering the microservices deployment, including authentication, authorization, throttling, and message content validation for known security threats. We get into the details of each topic in chapters 3, 4, and 5.
Figure 1.6 Multiple security enforcement points at multiple layers help improve the level of security of a microservices deployment.
The network perimeter level is where you should have the best defense against DoS/DDoS attacks. A firewall is one option; it runs at the edge of the network and can be used to keep malicious users away. But firewalls can’t protect you completely from a DDoS attack. Specialized vendors provide DDoS prevention solutions for use outside corporate firewalls. You need to worry about those solutions only if you expose your system to the internet. Also, all the DDoS protection measures you take at the edge aren’t specific to microservices. Any endpoint that’s exposed to the internet must be protected from DoS/DDoS attacks.
1.3.6 Authorization: Nothing more than you’re supposed to do
Authentication helps you learn about the user or the requesting party. Authorization determines the actions that an authenticated user can perform on the system. In an e-commerce application, for example, any customer who logs into the system can place an order, but only the inventory managers can update the inventory.
In a typical microservices deployment, authorization can happen at the edge (the entry point to the microservices deployment, which could be intercepted by a gateway) and at each service level. In section 1.4.3, we discuss how authorization policies are enforced at the edge and your options for enforcing authorization policies in service-to-service communication at the service level.
1.4 Edge security
In a typical microservices deployment, microservices are not exposed directly to client applications. In most cases, microservices are behind a set of APIs that is exposed to the outside world via an API gateway. The API gateway is the entry point to the microservices deployment, which screens all incoming messages for security.
Figure depicts a microservices deployment that resembles Netflix’s, in which all the microservices are fronted by the Zuul API gateway.9 Zuul provides dynamic routing, monitoring, resiliency, security, and more. It acts as the front door to Netflix’s server infrastructure, handling traffic from Netflix users around the world. In figure 1.7, Zuul is used to expose the Order Processing microservice via an API. Other microservices in the deployment, Inventory and Delivery, don’t need to be exposed from the API gateway because they don’t need to be invoked by external applications.
T
The role of an API gateway in a microservices deployment
The key role of the API gateway in a microservices deployment is to expose a selected set of microservices to the outside world as APIs and build quality-of-service (QoS) features. These QoS features are security, throttling, and analytics.
CERTIFICATE-BASED AUTHENTICATION
communication between the API gateway and the microservices is system to system, so you probably can use mTLS authentication to secure the channel. But how do you pass the user context to the upstream microservices? You have a couple of options: pass the user context in an HTTP header, or create a JWT with the user data. The first option is straightforward but raises some trust concerns when the first microservice passes the same user context in an HTTP header to another microservice. The second microservice doesn’t have any guarantee that the user context isn’t altered. But with JWT, you have an assurance that a man in the middle can’t change its content and go undetected, because the issuer of the JWT signs it.
In most cases, synchronous communication happens over HTTP. Asynchronous communication can happen over any kind of messaging system, such as RabbitMQ, Kafka, ActiveMQ, or even Amazon Simple Queue Service (SQS).
Service-to-service authentication
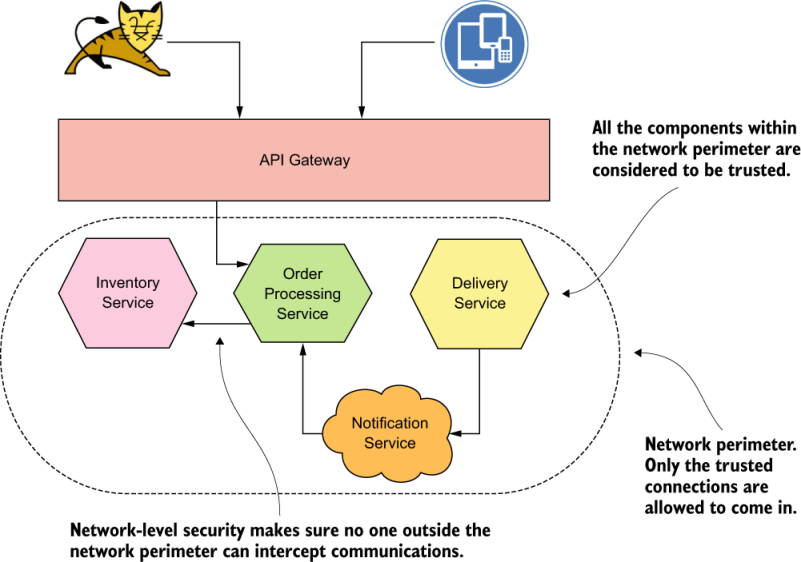
The trusted network makes sure that communications among microservices are secured. No one on a system outside the trusted network can see the traffic flows among microservices in the trusted network.
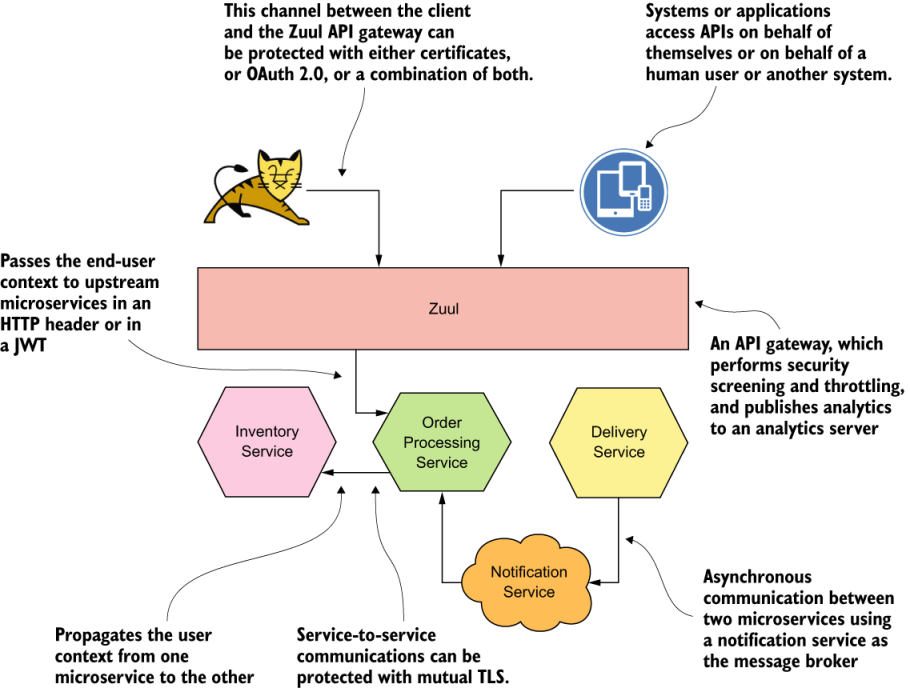
Communications among microservices are secured with mTLS. All the microservices that communicate with each other trust the certificate authority (CA) in the deployment.
JSON WEB TOKENS
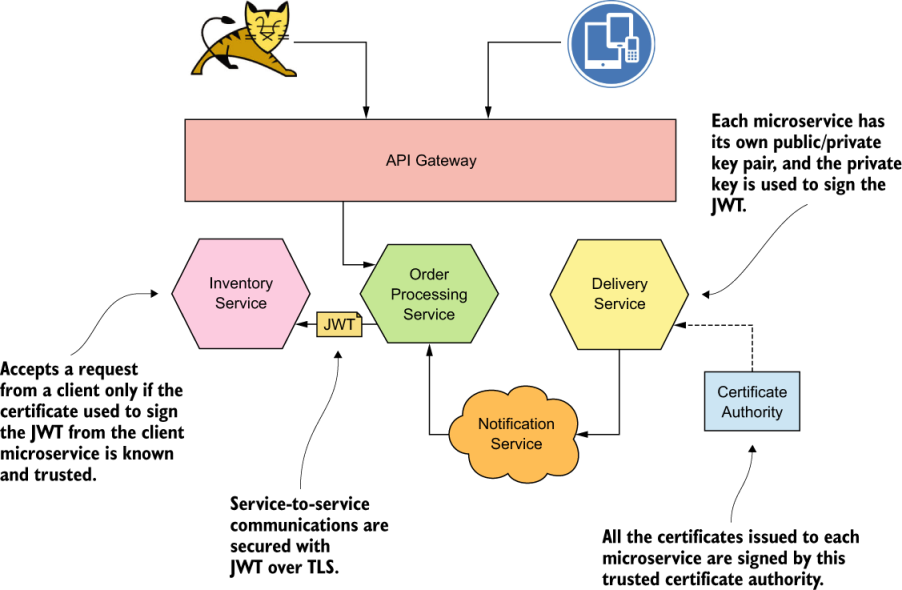
Communications among microservices are secured with JWT. Each microservice uses a certificate issued to it by the certificate authority to sign JWTs.
No comments:
Post a Comment